本文是自己开发Hive经验的总结,希望对大家有所帮助,有问题请留言交流。
Hive开发经验思维导图

文档目录
- 向Hive程序传递变量的方式
- 方法1:字符串、正则、模板引擎等暴力方式替换
- 方法2:使用系统变量或者环境变量
- 方法3:在执行Hive命令时传入hivevar和hiveconf
- Order by和Sort by的区别?
- 遇到SQL无法实现的逻辑该怎么办?
- 怎样使用脚本语言来扩展HIVE
- Hive任务执行很慢,但是导入数据非常的快?
- 要读取的数据是tar.gz的格式怎么办?
- 已经有了Partitoin,为什么需要Bucket?
- 字段类型设置的越宽泛当然更好了?
- 有哪些针对HIVE的优化方法
- Join时大表写在最后
- 如果Join表数据量小,使用MapJoin
- 数据的思维,多使用临时表
- 怎样实现In语法
- 其他的一些技巧
- 删除整个数据库的方法
- 查看数据表的详细信息
- Hive中可以执行shell和hadoop dfs命令
- union all在数据对齐中的使用
- NULL和数字相加的问题
- 增加数据到HIVE表的两种方法
1. 向Hive程序传递变量的方式
使用Hive编写程序最常用的方法是将Hive语句写到文件中,然后使用hive -f filename.hql来批量执行查询语句。经常需要将外部参数传入到hql语句中替换其中的变量来动态执行任务,比如动态设定数据库名、表名、时间值、字段序列等变量,以达到脚本泛化执行的目的。
方法1:字符串、正则、模板引擎等暴力方式替换
最简单也最暴力的方式,是在hql文件中设定{table_name}这样的变量占位符,然后使用调度程序比如shell、python、java语言读取整个hql文件到一个字符串,替换其中的变量。然后使用hive -e cmd_str来执行该Hive命令字符串。举例代码如表格 1和表格 2所示。
表格 1 hive ql文件内容
# 来源:疯狂的蚂蚁www.crazyant.net
use test;
select * from student limit {limit_count};
表格 2 Python脚本读取、替换和执行Hive程序
import os
#step1: 读取query.ql整个文件的内容
ql_source=open("query.ql","r").read()
#step2:替换其中的占位符变量
ql_target=ql_source.replace("{limit_count}","10")
#step3:使用hive -e的方法执行替换后的Hql语句序列
os.system("hive -e '%s'"%ql_target)
方法2:使用系统变量或者环境变量
通常情况是使用shell来调度执行hive程序的,Hive提供了可以直接读取系统env和system变量的方法,如表格 3所示。
表格 3 使用env和system读取外部环境变量
use test;
--使用${env:varname}的方法读取shell中export的变量
select * from student limit ${env:g_limit_count};
--使用${system:varname}的方法读取系统的变量
select ${system:HOME} as my_home from student;
这种方式比较好,比如在shell中可以配置整个项目的各种路径变量,hive程序中使用env就可以直接读取这些配置了。
方法3:在执行Hive命令时传入hivevar和hiveconf
第3种方法是在用hive命令执行hive程序时传递命令行参数,使用-hivevar和-hiveconf两种参数选项给该次执行传入外部变量,其中hivevar是专门提供给用户自定义变量的,而hiveconf则包括了hive-site.xml中配置的hive全局变量。
表格 4 hivevar和hiveconf传递变量的方法
| hive -hivevar -f file | hive -hivevar tbname='a' -hivevar count=10 -f filename.hql |
| hive -hivevar -e cmd | hive -hivevar tbname='a' -hivevar count=10 -e 'select * from ${hivevar:tbname} limit ${hivevar:count}' |
| hive -hiveconf -f file | hive -hiveconf tbname='a' - hiveconf count=10 -f filename.hql |
| hive -hiveconf -e cmd | hive -hiveconf tbname='a' -hiveconf count=10 -e 'select * from ${hivevar:tbname} limit ${hivevar:count}' |
最经常使用的是env和-hivevar方法,前者直接在Hive脚本中读取shell export的变量,后者则对脚本的当前执行进行参数设置。
2. Order by和Sort by的区别?
Hive基于HADOOP执行分布式程序,和普通单机程序不同的一个特点就是最终的数据会产生多个子文件,每个reducer节点都会处理partition给自己的那份数据产生结果文件,这导致了在HADOOP环境下很难对数据进行全局排序,如果在HADOOP上进行order by全排序,会导致所有的数据集中在一台reducer节点上,然后进行排序,这样很可能会超过单个节点的磁盘和内存存储能力导致任务失败。
一种替代的方案则是放弃全局有序,而是分组有序,比如不求全百度最高的点击词排序,而是求每种产品线的最高点击词排序。
表格 5 使用order by会引发全局排序
select * from baidu_click order by click desc;
表格 6 使用distribute和sort进行分组排序
select * from baidu_click distribute by product_line sort by click desc;
distribute by + sort by就是该替代方案,被distribute by设定的字段为KEY,数据会被HASH分发到不同的reducer机器上,然后sort by会对同一个reducer机器上的每组数据进行局部排序。
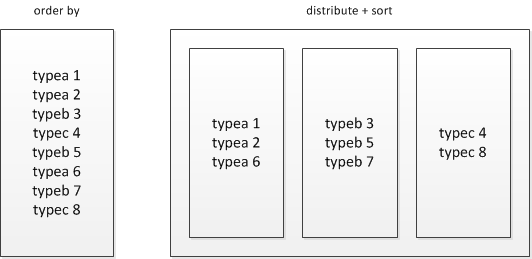
distribute+sort的结果是按组有序而全局无序的,输入数据经过了以下两个步骤的处理:
1) 根据KEY字段被HASH,相同组的数据被分发到相同的reducer节点;
2) 对每个组内部做排序
由于每组数据是按KEY进行HASH后的存储并且组内有序,其还可以有两种用途:
1) 直接作为HBASE的输入源,导入到HBASE;
2) 在distribute+sort后再进行orderby阶段,实现间接的全局排序;
不过即使是先distribute by然后sort by这样的操作,如果某个分组数据太大也会超出reduce节点的存储限制,常常会出现137内存溢出的错误,对大数据量的排序都是应该避免的。
3. 遇到SQL无法实现的逻辑该怎么办?
经常有Hive语句无法满足的需求,比如将日期20140319转换成2014Q1的季度字符串、先按照KEY进行group然后取每个分组的limt N值等情景,最直接的实现是使用Hive的提供的Java UDF接口来实现。
Hive共提供了以下三种类型的UDF,分别对应处理不同的场景:
表格 7 Hive提供的3种UDF类型
| UDF类型 | 名称 | 特点 | 举例 |
| UDF | 用户自定义函数 | 读取一行,返回单个值 | abs求单行某字段的绝对值 |
| UDAF | 用户自定义聚合函数 | 读取多行,返回单个值 | sum求多行的和 |
| UDTF | 用户自定义表生成函数 | 读取一行或多行,返回多行或这多列 | explode将一个字段变成多行,每个元素是一行 |
这三类函数,最常用是UDF,其次是UDAF,而UDTF一般都不会遇到,如下是一个UDF的编写与使用的完整实例,有以下几个特点:
- 继承apache.hadoop.hive.ql.exec.UDF父类;
- 覆盖Text evaluate(Text str)方法;
表格 8 将日期转换成季度字符串的UDF
package myudf;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
/**
* 来源:疯狂的蚂蚁 www.crazyant.net
* UDF处理一行数据,产生一行数据
* step1:用户需要继承UDF父类;step2:需要实现evalute方法用于被Hive回调;
* @author www.crazyant.net
*/
public class DateToQuarter extends UDF {
/**
* 把YYMMDD形式的日期字符串,转换成'2014Q1'形式的季度字符串;
* @param str 输入的日期
* @return '2014Q1'形式的季度字符串值
*/
public Text evaluate(Text str) {
if (str == null) return null;
//提取字符串中的年份和月份
String year = str.toString().substring(0, 4);
int month = Integer.parseInt(str.toString().substring(4, 6));
String quarter = "";
if (month >= 1 && month <= 3) {
quarter = "Q1";
} else if (month >= 4 && month <= 6) {
quarter = "Q2";
} else if (month >= 7 && month <= 9) {
quarter = "Q3";
} else if (month >= 10 && month <= 12) {
quarter = "Q4";
}
// 要返回的2014Q1季度字符串
return new Text(year + quarter);
}
}
表格 9 Hive使用UDF的语法
use test; add jar /home/users/crazyant/tmp/hive-udf-test-0.0.1-SNAPSHOT.jar; CREATE TEMPORARY FUNCTION datatoquarter as 'myudf.DateToQuarter.'; select sname, datatoquarter(enter_date) from student;
UDF和UTAF是两类非常常用的自定义函数,前者处理单个字段,后者处理多行合并为1个字段,如果熟悉JAVA可以用这种方法开发,优点是这些UDF程序会直接在MAP-REDUCE本身任务的JVM中运行效率较高,但是缺点在于开发复杂周期长,不如解释性语言如Python的开发高效。
4. 怎样使用脚本语言来扩展HIVE
除了JAVA也可以使用其它语言来编写Streaming程序扩展Hive,好处是开发速度快(省去了JAVA编译、打包等步骤),缺点是Hadoop会多启动一个子Streaming进程来和父Java进程来通信,导致性能的降低。
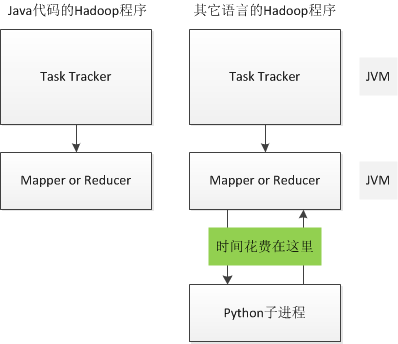
开发Hive的Streaming程序和开发Hadoop的Streaming程序是相同的,都是从标准输入中读取按\t分割的数据,将\t分割的结果写出到标准输出中
表格 10 Hive Streaming的Python脚本
# coding: utf8
'''
来源:疯狂的蚂蚁 www.crazyant.net
将日期字符串转换成季度字符串形式
输入:YYYYMMDD或者YYYY-MM-DD的日期形式;
返回:YYYYQ1、YYYYQ2、YYYYQ3、YYYYQ4,季度字符串形式
'''
import sys
def get_date_year_quarter_str(pdate):
'''获取日期的季度字符串形式
'''
(year_val, month_val) = (pdate[:4], pdate[4:6])
# 算出季度的序号
quarter_index = (int(month_val) - 1) / 3 + 1
quarter_str = "%sQ%d" % (year_val, quarter_index)
return quarter_str
def process_input():
'''主处理函数,每行最后一个字段是日期'''
for line in sys.stdin:
line = str(line).strip()
if not line: continue
fields = line.split("\t")
# 将YYYY-MM-DD转换成YYYYMMDD
date_val = str(fields[-1]).replace("-", "")
# 重新组装输出字段
output_fields = fields[:-1] + [get_date_year_quarter_str(date_val)]
print '\t'.join(output_fields)
if __name__ == "__main__":
process_input()
然后在Hive程序中可以这样调用该Steaming脚本
表格 11 Hive程序中调用Steaming的方法
use test;
-- 来源:疯狂的蚂蚁 www.crazyant.net
-- step1:以绝对路径的方式添加脚本
add file /home/users/crazyant/workbench/streaming/date_to_quarter.py;
-- step2:用TRANSFORM.. using.. as.. 句式调用
select
TRANSFORM (sname, birthday) using 'python date_to_quarter.py' as (sname, bir_quarter)
from student_info;
几个需要注意的地方:
- 需要用绝对路径的方法添加脚本文件;
- add file可以用于添加字典数据
- add file也是map join分发数据文件的方法
- select中除了TRANSFORM不能有其他的字段;
- 所有需要的字段都需要写在TRANSFORM中;
- 一个python脚本会处理该节点上所有的数据
- TRANSFORM一般都需要和distribute by.. sort by句式一起使用;
- 如果不用distribute by.. sort by句式,数据会被分到1个reduce节点上,造成单点负载过重;
- 因此该python脚本可以实现UTAF(多行聚合)和UDTF(1行变多行或多列)的;
5. Hive任务执行很慢,但是导入数据非常的快?
Hive使用Hadoop来执行查询,其查询执行速度是很慢的,但是使用load data向Hive中导入数据却非常快,这是因为Hive采取的是读时模式。
读时模式:读取数据的时候,对数据的类型、格式做检查;
写时模式:写入数据的时候,对数据的类型、格式等规范做检查;
将数据存到Hive的数据表时,Hive采用的是“读时模式”,意思是针对写操作不会做任何校验,只是简单的将文件复制到Hive的表对应的HDFS目录,如图 4所示。跟“读时模式”相对应的是“写时模式”,RDBMS一般采用“写时模式”,在将数据写入到数据表的时候会检查每一条记录是否合法,如果检查不通过会直接返回失败信息。
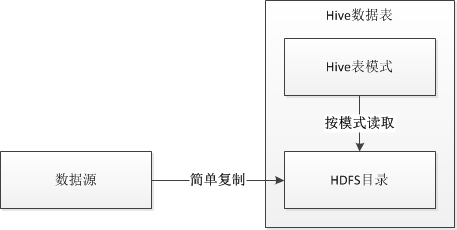
由于向Hive中存入数据的只是简单的文件复制和粘贴,所以导入数据速度非常的快。当读取、查询的时候,才会根据表模式来解释数据,这个时候如果遇到了不符合模式的数据,Hive会直接将数据解析成NULL。
Hive采用读时模式带来了以下几个好处:
- 向Hive表中新增数据非常的快,通常情况下对于外来数据,采用的方法是直接用Hadoop命令将文件上传到一个HDFS目录,Hive直接读这个目录;
- 一份数据可以被解析成多种模式,存储在Hive表中的数据跟Hive本身没有关系,数据也可以被其他工具比如Pig来处理;
6. 要读取的数据是tar.gz的格式怎么办?
HADOOP中存放的大部分都是日志数据,这些数据的字段重复率高,进行压缩的话能节省大量的存储空间,同时由于减少了网络传输带宽,使得任务的执行速率也会提升。
有没有方法读取压缩后的数据,比如tar.gz结尾的文件呢,答案是肯定的,并且不需要做任何操作就可以读取。HADOOP默认已经安装了编码解码器,并且是自动加载的。使用如下命令可以查看当前HADOOP安装的编解码器:
表 1 Hive客户端默认安装的编码解码器
hive> set io.compression.codecs; io.compression.codecs= org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.LzopCodec, org.apache.hadoop.io.compress.LzoCodec, org.apache.hadoop.io.compress.LzmaCodec, org.apache.hadoop.io.compress.QuickLzCodec
其中GzipCodec用于对.tar.gz文件进行压缩和解压。
不同的编解码文件规则也是不同的,比如gzip文件由于压缩的时候掩盖了文件边缘信息,导致这个文件如果按大小拆分后会乱码,因此每个gzip文件如果特别大,就不适合做HADOOP计算。这样的文件可以采用另外的Bzip2进行压缩,这种格式用限定大小比如64MB的方法拆分后,每个分片都是独立完整能够读取的。
对于HADOOP的计算,有以下的三种压缩:
- 输入数据压缩:比如对原始日志进行压缩,目的是节省HDFS存储空间;
- 中间过程压缩:对MAP的结果进行压缩,传输到REDUCE节点后解压缩,然后进行计算,可以节省网络传输时间,不过解压缩会耗费CPU。HADOOP由于大部分计算是IO密集型而非CPU密集型,因此这种方法也会使用;
- 输出结果压缩:目的也是节省存储空间,同时方便后续的其他任务快速读取和处理;
7. 已经有了Partitoin,为什么需要Bucket?
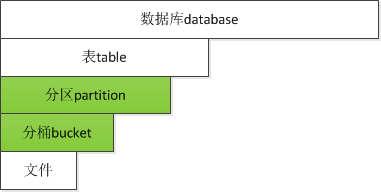
如图 5是Hive的数据结构划分,从大到小依次是:
- 数据库database:对应HDFS上的最顶层目录,类似MySQL的数据库;
- 表table:对应数据库下面的文件夹,表下面可以直接放数据,对应MySQL的表;
- 分区partition:是对表按照某一维度进行的分表存储,比如各个省份的数据分别是一张表、或者每天一个分区,对应MySQL的分表概念;
- 分桶bucket:是对数据按照某一字段进行HASH分开存储的结果,比如如果按照账号ID进行2个bucket存储,那么账号ID是奇数或者偶数,会分开存到两个不同的篮子中;
- 文件:这个文件代表原始数据,可以放在篮子中,也可以放在partion和table中。
由此可以看出,partition和bucket的概念是类似的,不过也有所不同。bucket是对partion的更深一层HASH划分,并且可以限定HASH的桶数。如果按照日期分区,那么每天都是一个partition一直增长下去,但是如果限定30个bucket,不论多少数据,都会分开放在这30个bucket中。
同时分桶的概念,也是为了解决分区的一个问题,比如可以按照天、季度、省份等对数据分区,因为这些分类都是可控的,但是无法对账号进行分区,这样的分区数目会太大超过Inode数目限制。
分桶的出现有以下优点:
- 解决一些数据无法分区问题,比如不能按账号分区,但是可以把账号数据分成N个桶;
- 桶的数据量是固定的,所以不会有数据波动;
- 每个桶中是一类数据,适合抽样;
- 分桶有利于高效的Map join,比如两个表都按照账号ID分成了30个桶,那么可以肯定同一个账号肯定都在对应的桶里面,这样就实现了分桶JOIN。
8. 字段类型设置的越宽泛当然更好了?
Hive遵从读时模式,不论表模式定义成什么样子,存储的数据量是不变的。于是为了表模式的可扩展性,很容易将字段类型设置成最宽泛,比如只要是数字就设置成bigint,理由就是“数据量并没有因为我设置更大的范围类型而存储变大,当然设置越宽泛越好”。
字段类型确实没有影响到数据的存储,但是影响到了数据的计算。
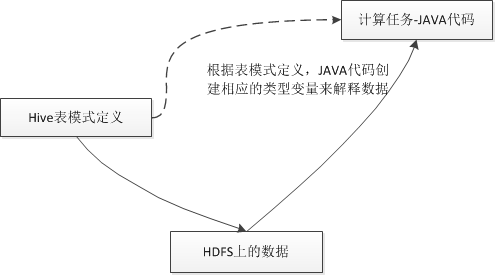
由于Hive底层是执行的Hadoop程序是使用Java来实现的,将Hive的执行命令转化成Hive语句执行时,会将表字段的类型映射到Java中的变量,比如Hive中的int会映射到Java中的Int,但是Hive中的bigint会映射到Java中的Long。
当程序被分发到上千的机器节点上的时候,由于分配的是long类型而不是更合适的int类型,会造成整体的内存耗费量大幅增加,最终的结果就是Hive的执行效率降低了。
如果确认能够用更小的类型表示字段,就不要用更宽泛的类型。
9. 有哪些针对HIVE的优化方法
Join时大表写在最后
执行例如tablea join tableb join tablec的Hive join语句是,Hive会将table和tableb都全部加载到内存,然后逐行扫描tablec进行Join,因此写Join语句时一定把大表写在最后。
如果Join表数据量小,使用MapJoin
如果确认用于Join的表数据量很小,比如只有100MB大小,可以使用/*+ MAPJOIN(a) */语法,这样Hive会先将小表分发到所有reducer节点的分布式缓存中并加载到内存,然后进行Join操作,由于减少了shuffle操作,性能有所提升。
表 2 使用mapjoin的方法
SELECT /*+ MAPJOIN(a) */ tablea.id, tableb.name FROM tablea join tableb on (tablea.id=tableb.id);
数据的思维,多使用临时表
和关系数据库不同,Hive最终是对磁盘上的文件进行扫描处理,应该用数据处理的思维来待这些SQL。如果一个表很大,但是只用到了其中的一部分列字段,那么最好先建立一个临时表,该临时表的字段是大表的有效字段。这样会减少大表的重复扫描来提升性能。不过临时表太多也是Hive的一个确定,这也是Pig其实更适合用于ETL处理的一个对比。
怎样实现In语法
Hive没有提供IN语法,比如in(select)的语句都会报错,但是这种需求是存在的。其实可以通过left semi join来实现。
比如有这么两个数据表:
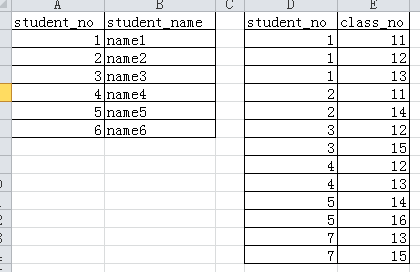
对这两个表执行下面的left semi join操作:
表 3 left semi join实现IN语法的方法
SELECT * FROM table1 LEFT semi JOIN table2 ON ( table1.student_no = table2.student_no);
会得到如下的执行结果:
1 name1
2 name2
3 name3
4 name4
5 name5
该结果和使用in(select)结果是相同的。
10. 其他的一些技巧
删除整个数据库的方法
当数据库存在表时,先要删除表再能删除数据库,不过加上CASCADE关键字会递归的删除整个数据库:DROP DATABASE test_db CASCADE;
查看数据表的详细信息
可以有3种方法查看数据表的信息,分别是desc student_info; desc extended student_info; desc formatted student_info;第1种显示最简单的字段信息,第2种除了显示字段信息还显示数据存放位置、输入输出格式等详细信息,第3种则是用格式化的方法显示详细信息,更方便查看。
Hive中可以执行shell和hadoop dfs命令
在hive程序中可以直接执行shell命令和hadoop命令,并且因为这些HADOOP命令会直接共用Hive的当前JVM,执行速度会更快;
表格 12 在Hive环境下能更快速的执行Hadoop命令
hive> dfs -ls /app/ecom;
union all在数据对齐中的使用
常常会遇到来自很多数据源的数据,每份数据都有相似的格式,并且处理逻辑也是相同的。可以用union all先将各份数据对齐后存储到一个表中,后续再对这个大表进行统一处理。
NULL和数字相加的问题
如果有用到sum函数,但是发现sum的列中有NULL值,可以使用以下方法转换成0值:COALESCE(f, cast(0 AS bigint)),coalesce方法会返回列表中第一个不为NULL的字段,相当于如果第一个字段是NULL,就第二个字段。
增加数据到HIVE表的两种方法
如果是外部数据,可以用external外部表,每天用hadoop fs -put的方法将数据复制到表目录中即可,这样也可以用于除了Hive的其他程序读取;
如果是中间表、临时表、产出表,则可以使用内部表,每天计算全量覆盖这些表内容;
本文地址:http://crazyant.net/1625.html ,转载请注明出处,谢谢。
本文也有PDF格式的文档,文字更清晰,只是图片不能放大,下载地址:http://pan.baidu.com/s/1sjpwjSh
很棒的文章,感谢楼主的经验分享。