Word2vec会产出每个词语的权重向量
使用这个向量,可以直接对所有的词语聚类
以下代码,以word2vec的model作为输入,进行kmeans训练,同时进行K的迭代计算,选出WSSSE最小的K值
/**
* 将word2vec的结果,作为kmeans的输入进行聚类;进行K的多次迭代,选出WSSSE最小的K
* @param spark
* @param model
*/
def word2vecToKmeans(spark: SparkSession, model: org.apache.spark.mllib.feature.Word2VecModel) = {
import org.apache.spark.mllib.clustering.{KMeans, KMeansModel}
import org.apache.spark.mllib.linalg.Vectors
// val parsedData = data.map(s => Vectors.dense(s.split(' ').map(_.toDouble))).cache()
val parsedData = model.getVectors.map(row => Vectors.dense(row._2.map(_.toDouble))).toSeq
val parsedDataRDD = spark.sparkContext.parallelize(parsedData).cache()
// Cluster the data into two classes using KMeans
val numKList = 2 to 20
numKList.foreach(
k => {
val numIterations = 50
val clusters = KMeans.train(parsedDataRDD, k, numIterations)
// Evaluate clustering by computing Within Set Sum of Squared Errors
val WSSSE = clusters.computeCost(parsedDataRDD)
println(s"K==${k}, Within Set Sum of Squared Errors = $WSSSE")
}
)
}
这里使用的是mllib的库
算出来的K值和WSSSE的对应关系为:
2 737409.9793517443 3 680667.1717807942 4 646796.9586209953 5 621979.831387794 6 600079.2948154274 7 583517.901818578 8 568308.9391577758 9 558225.3643934435 10 553948.317112428 11 548844.8163327919 12 534551.2249848123 13 530924.4903488192 14 525710.9272857339 15 523946.17442620965 16 516929.85870202346 17 511611.2490293131 18 510014.93372050225 19 503478.81601442746 20 500293.188117236
使用如下代码进行绘图:
#coding:utf8
import matplotlib.pyplot as plt
x = []
wssse = []
for line in open("kmeans_k_wssse.txt"):
line = line[:-1]
fields = line.split("\t")
if len(fields) != 2:
continue
x.append(int(fields[0]))
wssse.append(float(fields[1]))
plt.xlabel('k')
plt.ylabel('SSE')
plt.plot(x,wssse,'o-')
plt.show()
图片如下:
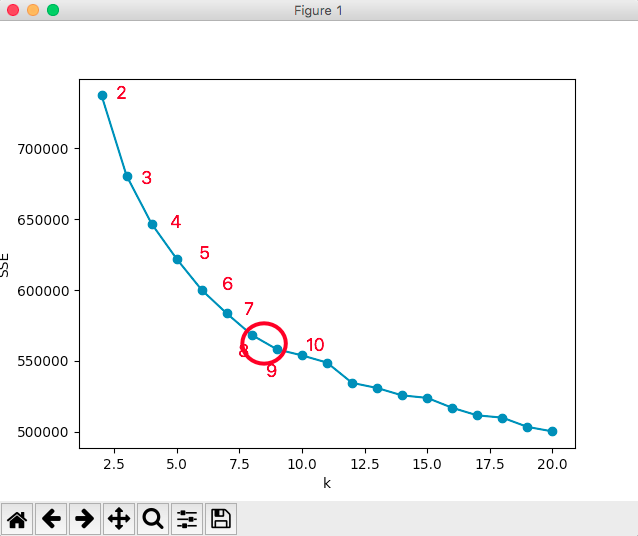
并不是完美的手肘,不过拐点大概在8、9的位置,以8或者9来聚类比较合适
也可以打印距离每个中心的10个数据
val distData = model.getVectors.map(row => {
val word = row._1
val probVector = Vectors.dense(row._2.map(_.toDouble))
val predictK = clusters.predict(probVector)
val centerVector = clusters.clusterCenters(predictK)
// 计算当前点,到当前中心的距离
val dist = Vectors.sqdist(probVector, centerVector)
(predictK, word, dist)
}).toSeq
val distRdd = spark.sparkContext.parallelize(distData)
val groupData = distRdd.map(row => (row._1, (row._2, row._3))).groupByKey()
// 打印距离每个中心的10个点
groupData.map(row => {
(row._1, row._2.toList.sortWith((a, b) => a._2 < b._2).take(10))
}).collect().foreach(row => {
row._2.foreach(
row2 => println(s"${row._1}\t${row2._1}\t${row2._2}")
)
})
然而,查看数据,并不能得到为啥这么分类,聚类的结果不好分析~~
参考文章:
用手肘法选出最佳的kmeans的K值:https://blog.csdn.net/qq_15738501/article/details/79036255
K-MEANS-SPARK文档:https://spark.apache.org/docs/2.2.0/mllib-clustering.html#k-means