背景
有很多爬虫,是需要登录后才能获取数据的。
登录框非常复杂,有验证码登录、扫码登录、短信登录,如果要通过技术手段搞定这些自动化登录,难度非常大。
人工和自动配合的方案
一个简单的替代方案,在登录的时候采用人工登录,然后程序自动保存Cookies数据文件,之后采用Selenium和Requests加载Cookies即可实现登录爬取。
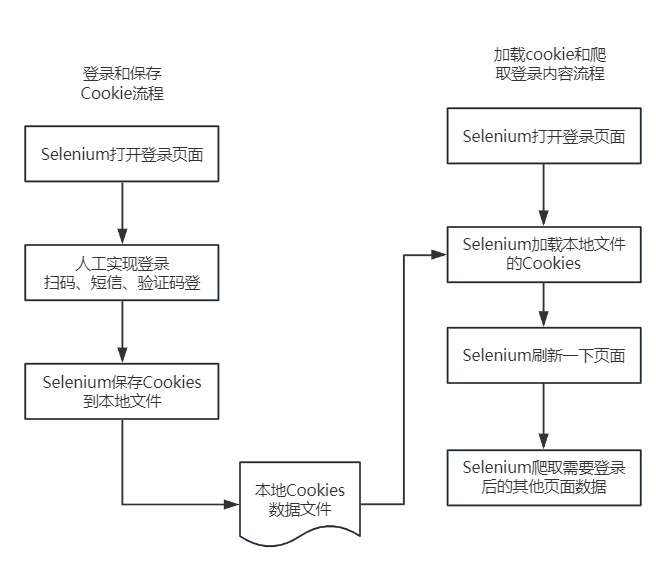
步骤1:Selenium打开页面人工登录
代码为:
from selenium import webdriver
import time
import json
driver = webdriver.Chrome()
def save_cookies(driver):
"""
1. 打开登录页面;2. 人工登录;3. 自动保存Cookies到本地文件
"""
# 最大化窗口
driver.maximize_window()
# 1. 打开登录的URL
driver.get("http://antcoding.net/login/")
# 2. Sleep 15秒钟,等待用户扫码
time.sleep(15)
# 3. 将登录后的cookies保存到本地文件
with open("cookies.txt", "w", encoding="utf8") as f:
f.write(json.dumps(driver.get_cookies(), indent=4, ensure_ascii=False))
driver.close()
这段代码的执行,首先会打开登录页面。
在15秒钟内,我们可以人工登录。
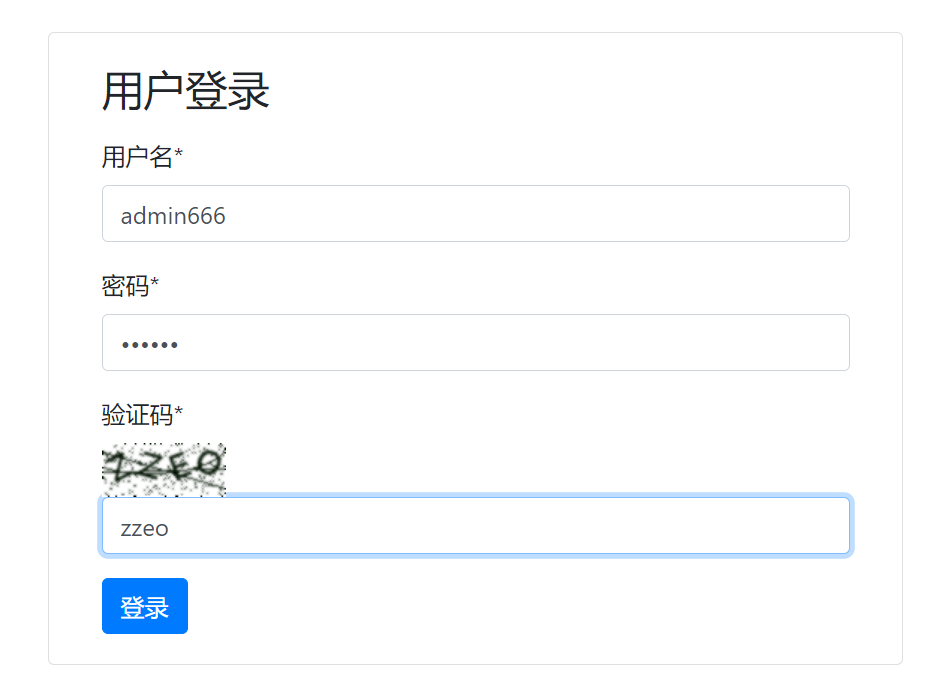
人工登录后,会在本地目录多了一个cookies.txt文件,打开后,里面是保存的Cookies的数据,形如:
[
{
"domain": "antcoding.net",
"expiry": 1710234549,
"httpOnly": true,
"name": "sessionid",
"path": "/",
"sameSite": "Lax",
"secure": false,
"value": "20nbta5wf17w5ozz6z2y1as51hob6od9"
},
{
"domain": "antcoding.net",
"expiry": 1740474549,
"httpOnly": false,
"name": "csrftoken",
"path": "/",
"sameSite": "Lax",
"secure": false,
"value": "OOrKTpZPFhBf3TcHJPC2gAyIm4ydtmEH"
}
]这一步就结束了,这个保存的Cookies文件可以被多次加载使用。
如果将来Cookies过期了,则可以重新执行这个程序,重新人工登录和保存一遍Cookies。
加载保存的Cookies文件,访问登录后的页面
import json
from selenium import webdriver
import pandas as pd
driver = webdriver.Chrome()
def load_cookies(driver):
"""
1. 访问一下登录的URL;2. 加载本地的Cookies;3. 刷新一下浏览器;
"""
# 最大化窗口
driver.maximize_window()
# 访问一下登录的URL
driver.get("http://antcoding.net/login/")
# 读取本地的Cookies文件,加载到driver
with open("cookies.txt", encoding="utf8") as f:
cookies = json.loads(f.read())
for cookie in cookies:
driver.add_cookie(cookie)
# 刷新一下浏览器
driver.refresh()
load_cookies(driver)
# 直接访问需要登录的页面
driver.get("http://antcoding.net/user_manage/")
# 读取这个页面的表格
df = pd.read_html(driver.page_source)[0]
print(df)
driver.close()
这段代码先加载本地的cookies文件,然后访问登陆后的页面。
其中登陆后的页面,样子为:
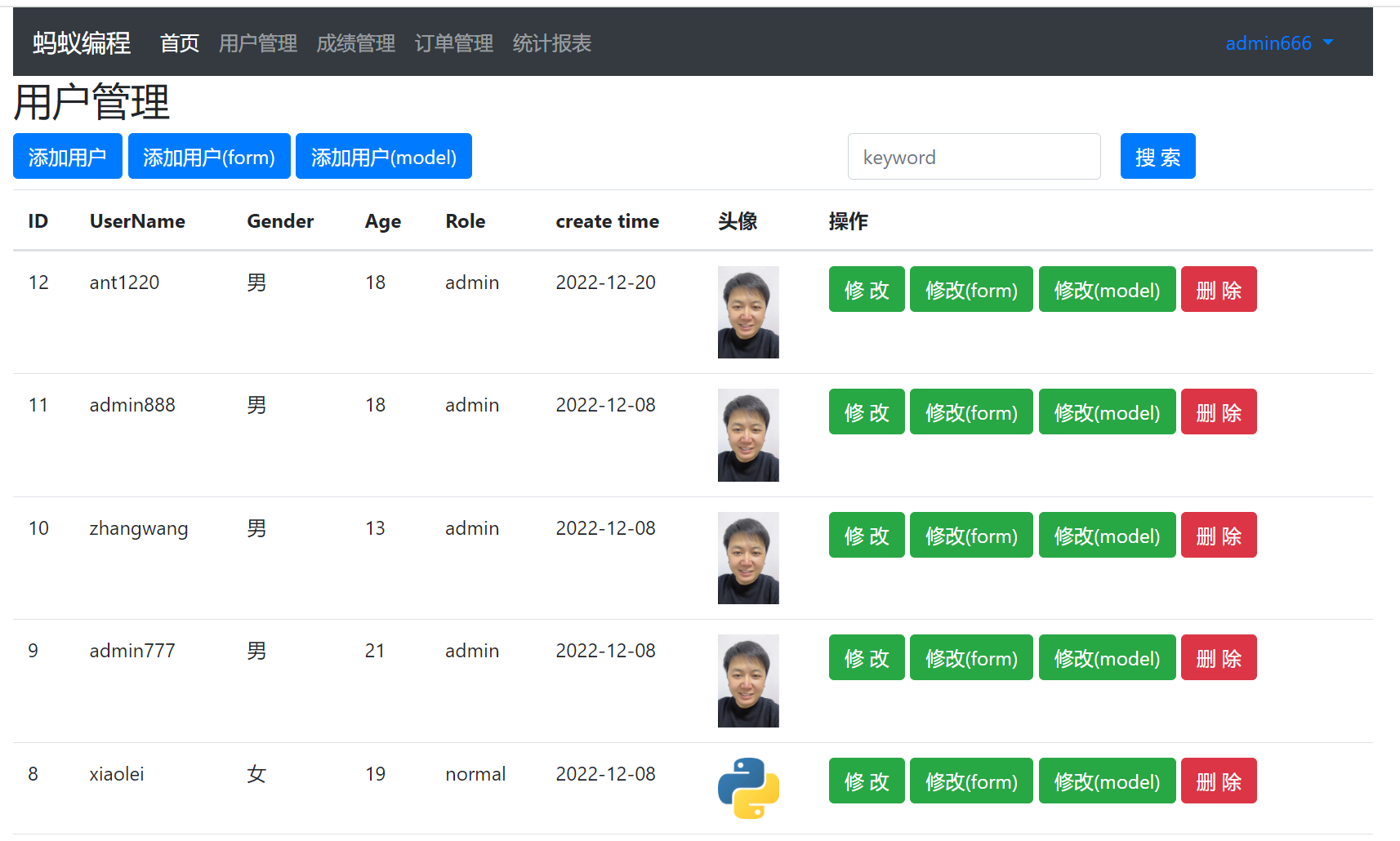
这段代码执行后,会直接打印这个页面的表格。这个表格是通过Pandas的方法做的解析和读取。
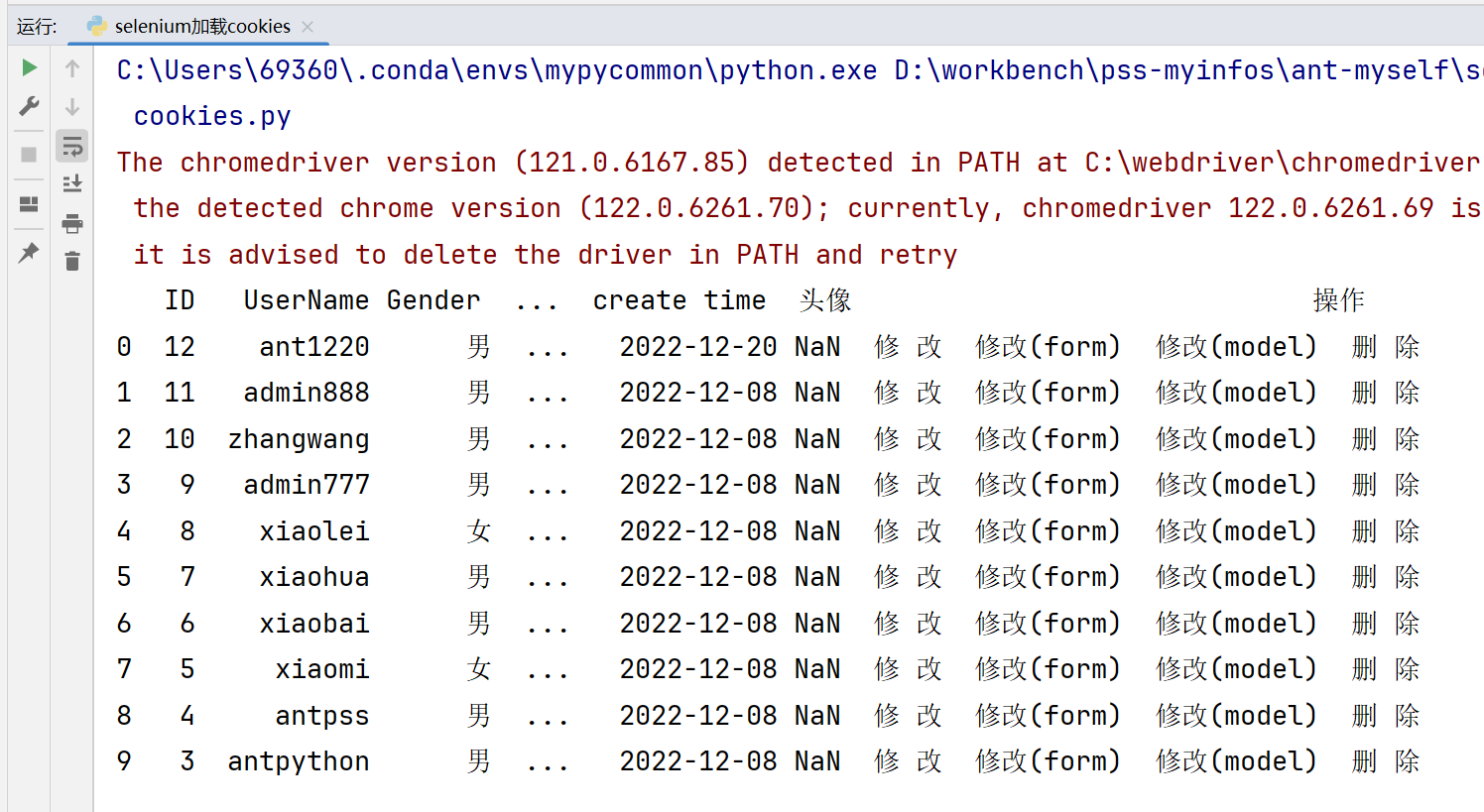
总结
这个方案的好处,是不用怕登录页面有多复杂,因为人工可以搞定登录难题,扫码、短信、复杂验证码都可以搞定。然后用程序保存的Cookies做之后的爬取。
需要注意的是,一般Cookies会在7天或者30天失效。失效后,需要重新执行第一个步骤,更新本地的Cookies文件的保存。
思路不错,学习了!
但是有一点,sleep 15s这里是否可以更改为检测主动关闭浏览器呢?
其实可以的,把time.sleep(15)改成selenium的wait语法,一直检测某个登录后的元素是否OK即可