先看下我的爬取成果:
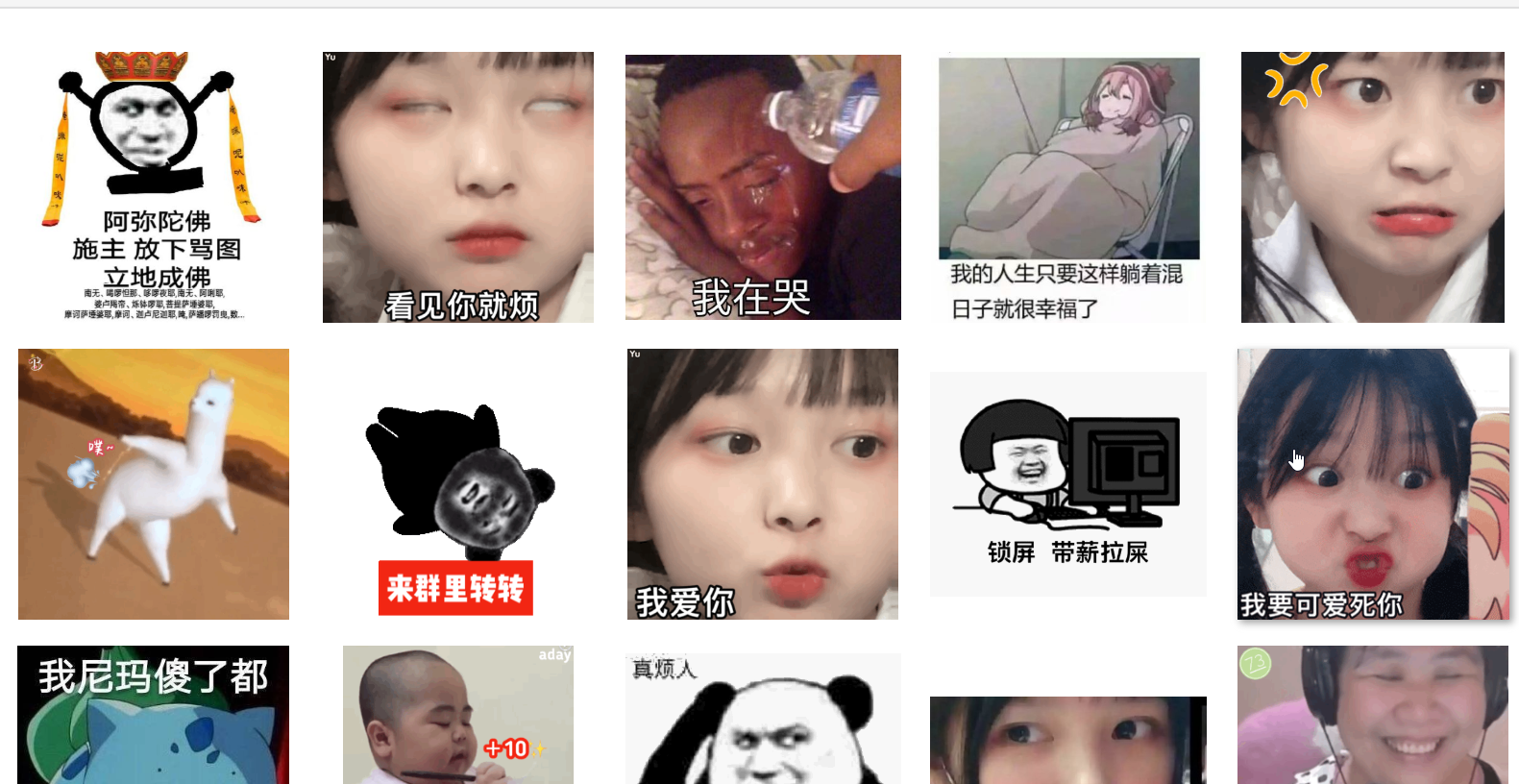
本视频的演示步骤:
- 使用requests爬取200个网页
- 使用BeautifulSoup实现图片的标题和地址解析
- 将图片下载到本地目录
这2个库的详细用法,请看我的其他视频课程
import requests
from bs4 import BeautifulSoup
import re1、下载共200个页面的HTML
def download_all_htmls():
"""
下载所有列表页面的HTML,用于后续的分析
"""
htmls = []
for idx in range(200):
url = f"https://fabiaoqing.com/biaoqing/lists/page/{idx+1}.html"
print("craw html:", url)
r = requests.get(url)
if r.status_code != 200:
raise Exception("error")
htmls.append(r.text)
print("success")
return htmls# 执行爬取
htmls = download_all_htmls()craw html: https://fabiaoqing.com/biaoqing/lists/page/1.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/2.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/3.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/4.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/188.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/189.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/190.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/191.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/192.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/193.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/194.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/195.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/196.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/197.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/198.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/199.html
craw html: https://fabiaoqing.com/biaoqing/lists/page/200.html
successhtmls[0][:1000]'\n\n\n \n \n \n \n 热门表情_发表情,表情包大全fabiaoqing.com \n \n \n \n \n \n \n
为什么显示找不到文件或路径呢
用了您的代码,文件会被下载到哪,我咋找不着emmmm初学者
就是在代码的当前目录
找不到,能具体点吗/还有图片所在文件夹名字是什么。非常谢谢