比如用户的分类偏好、用户的历史观影行为,都是变长的元素列表,怎么输入到模型?
这个问题很多人遇到,比如这些:
- Feeding variable length list data (from csv) to an 'indicator_column' feature
- How to input a list of lists with different sizes in tf.data.Dataset
有几种方法,但都还没有完美解决问题:
1、multi-onehot
自己创建一个大数组,把变长元素对应位置设置为1;
比如这个特征有两个值:
值1:a、b、c
值2:b、c、d
那么词表是a、b、c、d
值1就变成了[1,1,1,0],值2变成了[0,1,1,1]
这种方式最灵活,因为如果遇到了带有权重的分类列表,也能搞定:
比如
值1:[(a,0.8), (b,0.7), (c, 0.6)]
值2:[(b,0.5), (c, 0.4), (d, 0.3)]
那么词表依然是a、b、c、d,但是对应权重却可以放到原来为1的位置上;
值1变成了:[0.8, 0.7, 0.6, 0]
值2变成了:[0, 0.5, 0.4, 0.3]
然而这种方法tensorflow的feature column不支持,只能自己做映射转换
2、变成定长
以下两种方式,tensorflow的feature column可以支持
变成定长方法1:截取前TOP N个元素
来自资料:
http://proceedings.mlr.press/v7/niculescu09
有个PDF,看截图:

使用的方法,是先计算每个词语的频率,然后去TOP10的频率;
对于这种方法,个人感觉,如果是用户的分类偏好(分类,权重)列表,可以按照权重排序,取TOP10;
也可以提取定长10个元素,并且反映了用户个性化的偏好;
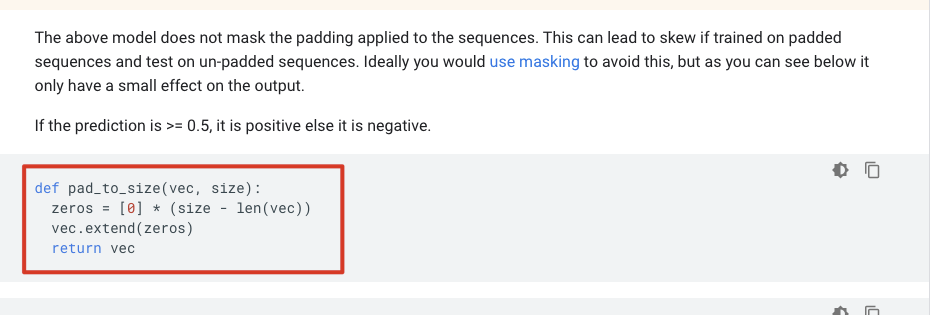
变成定长方法2:使用padding补0
来自资料:tensorflow的官方文档
https://www.tensorflow.org/tutorials/text/text_classification_rnn
这是用0补齐的方式;